05
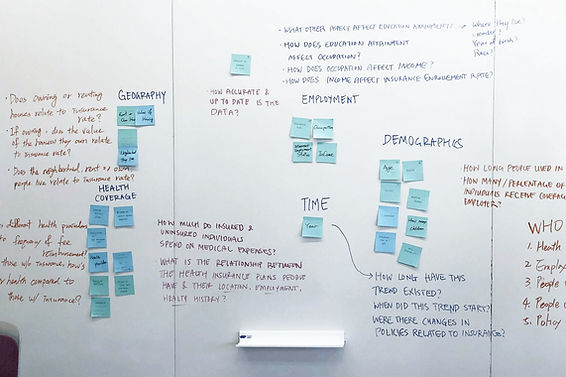
reflection
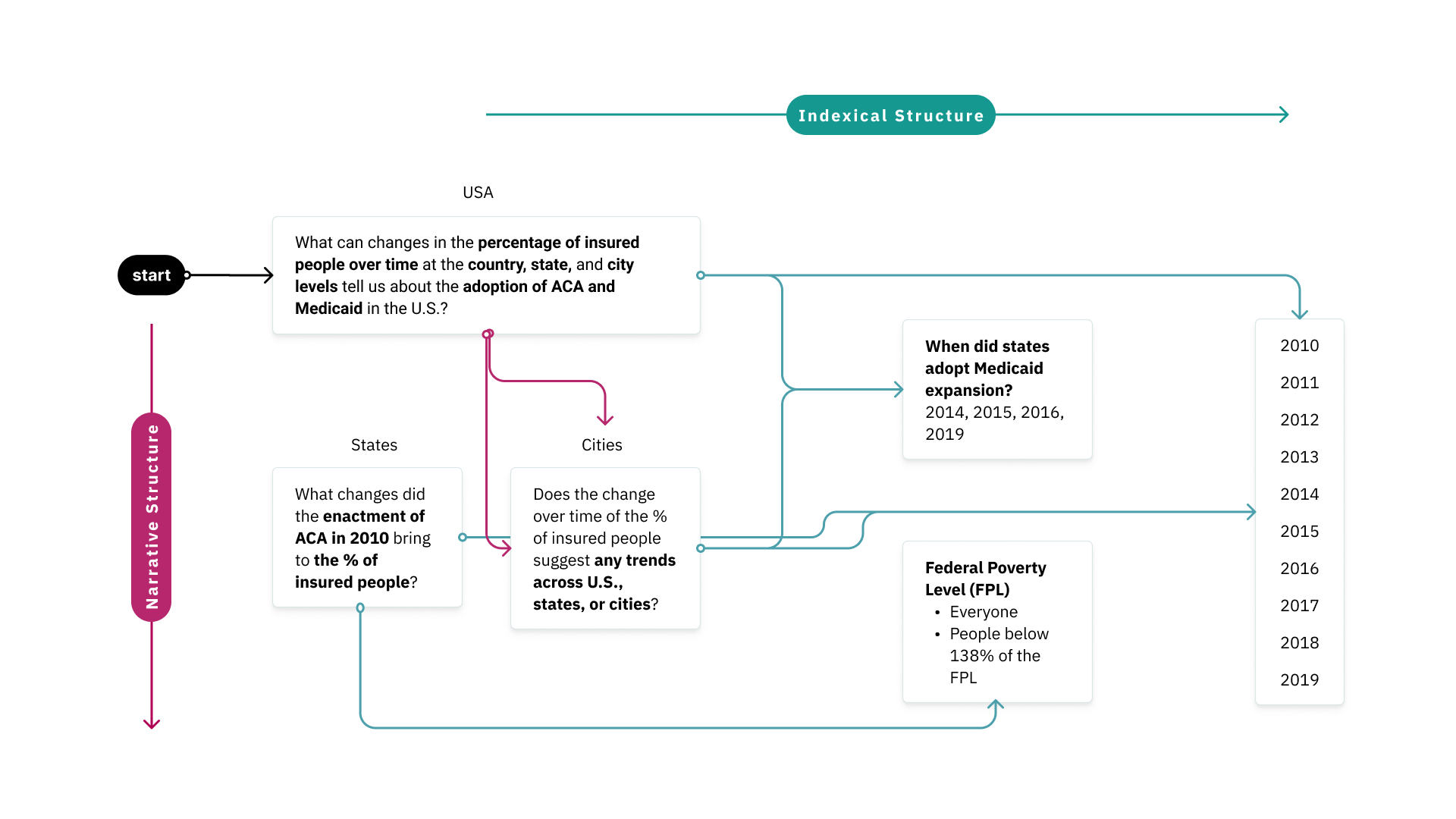
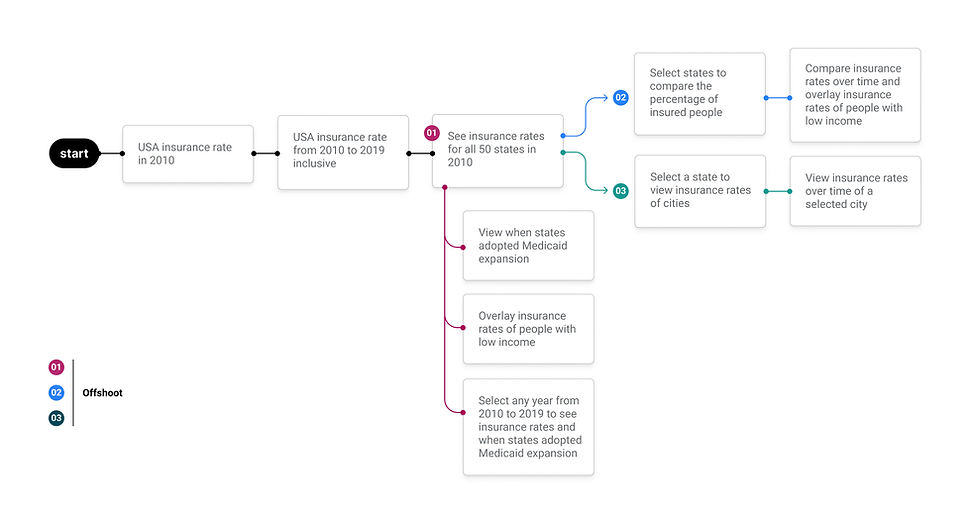
Questions we now raise
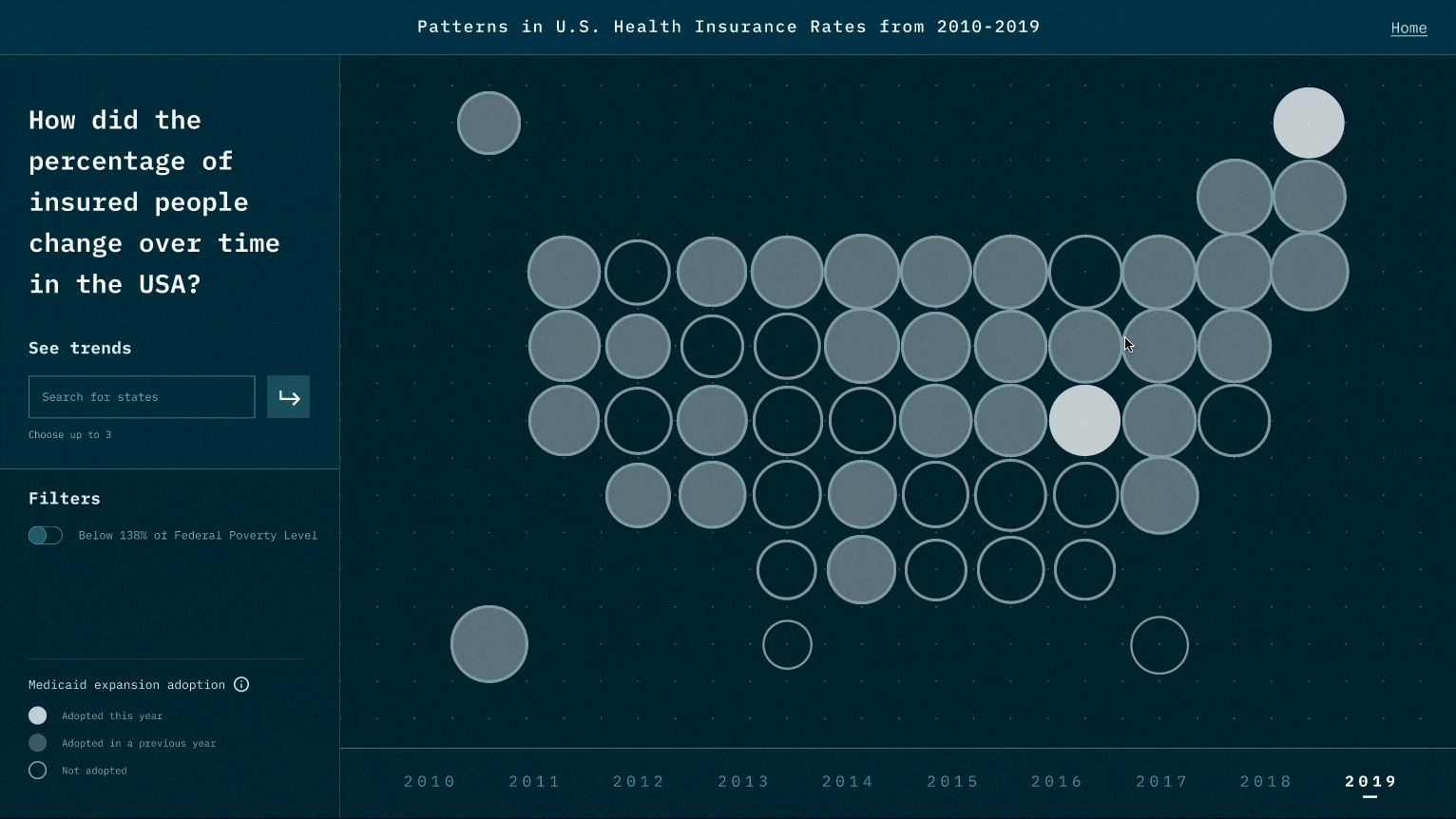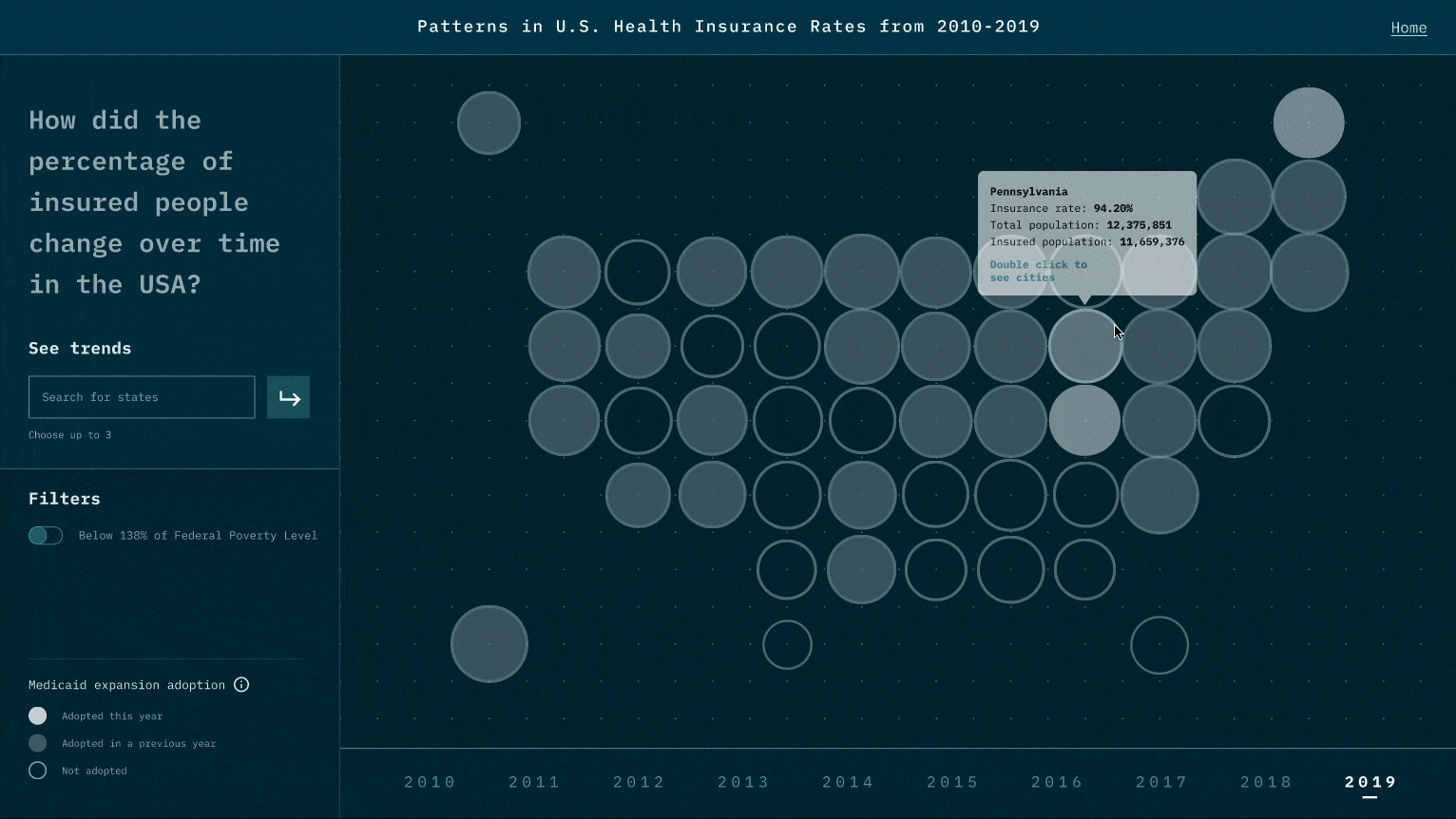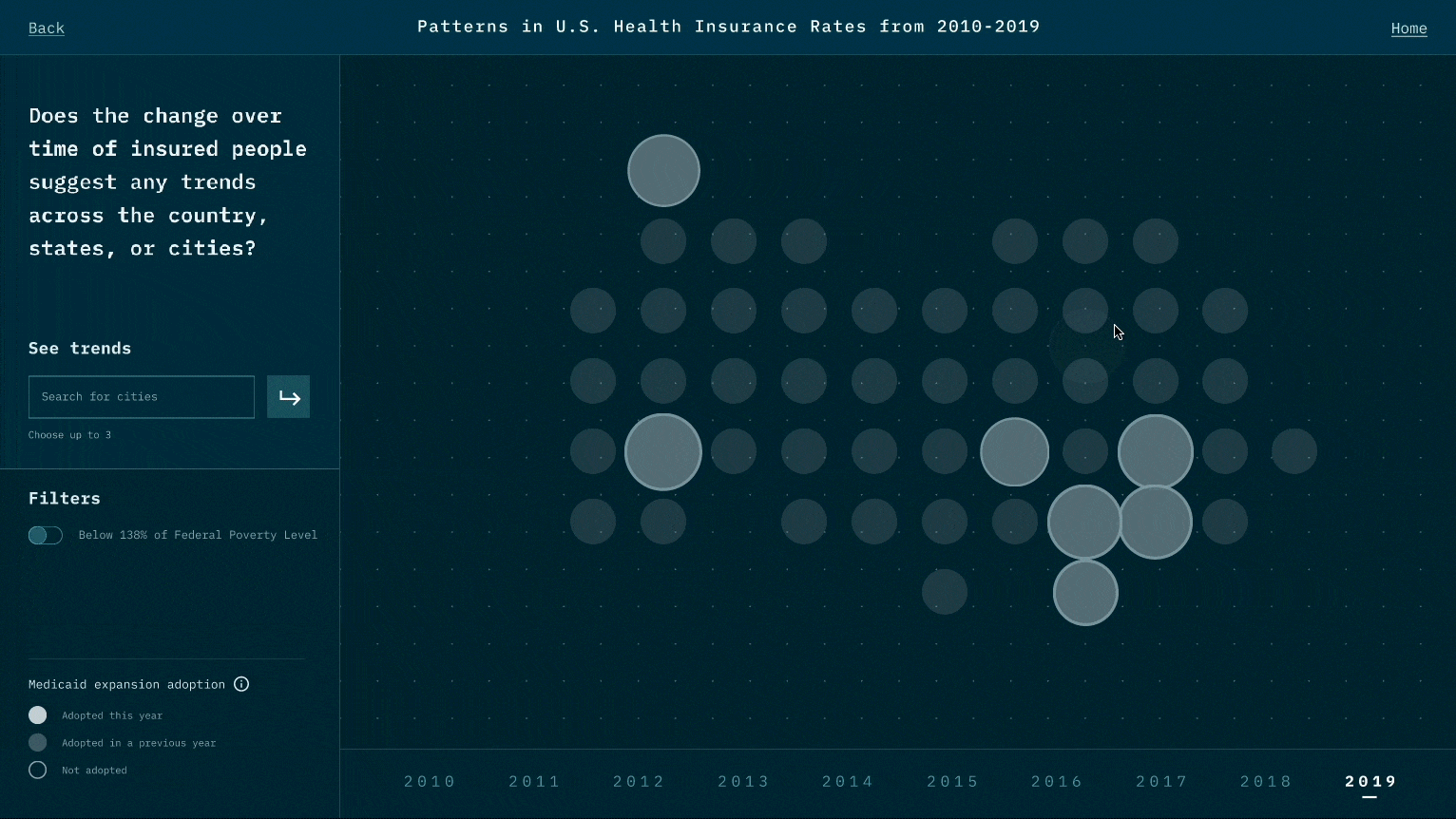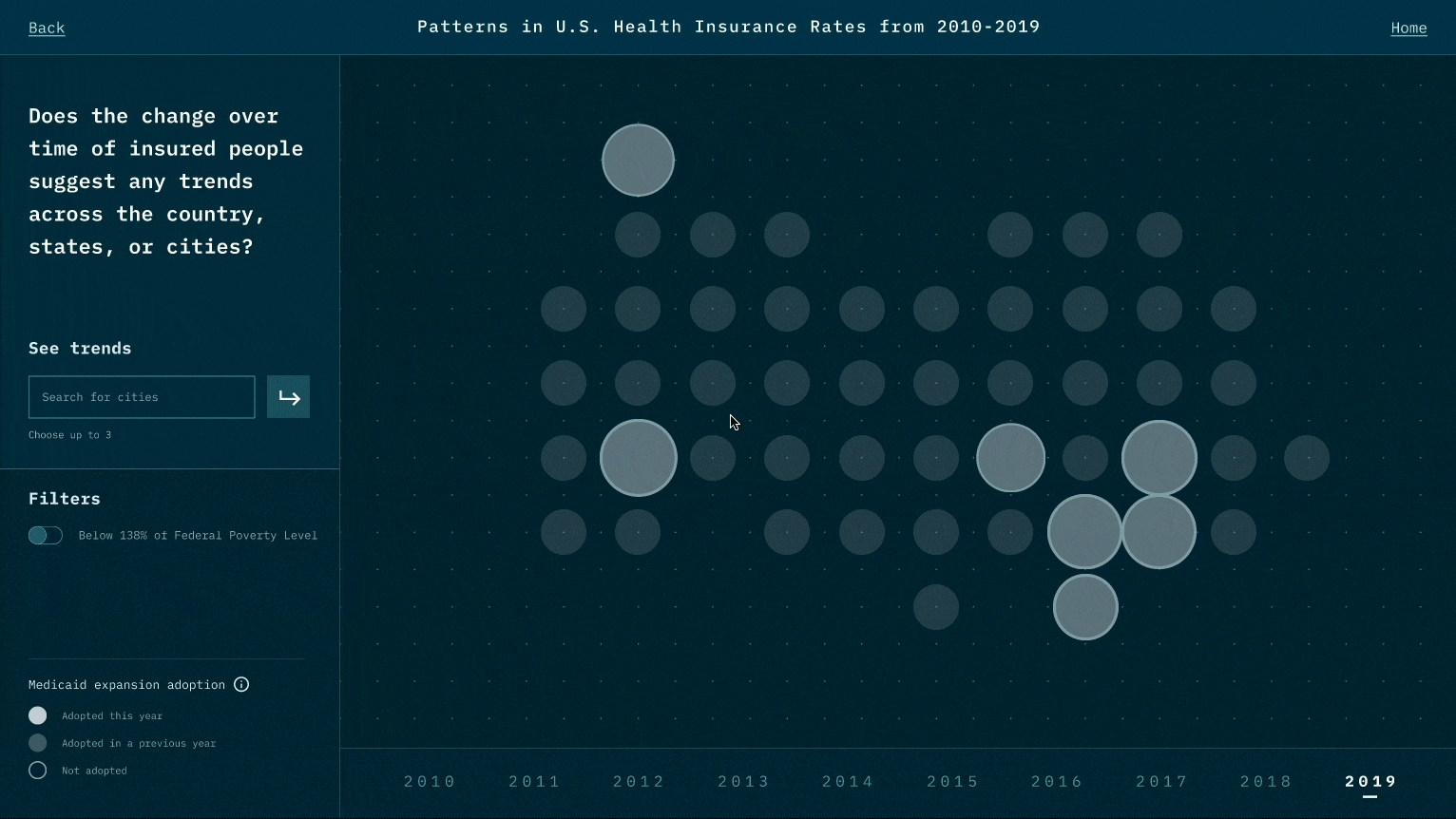
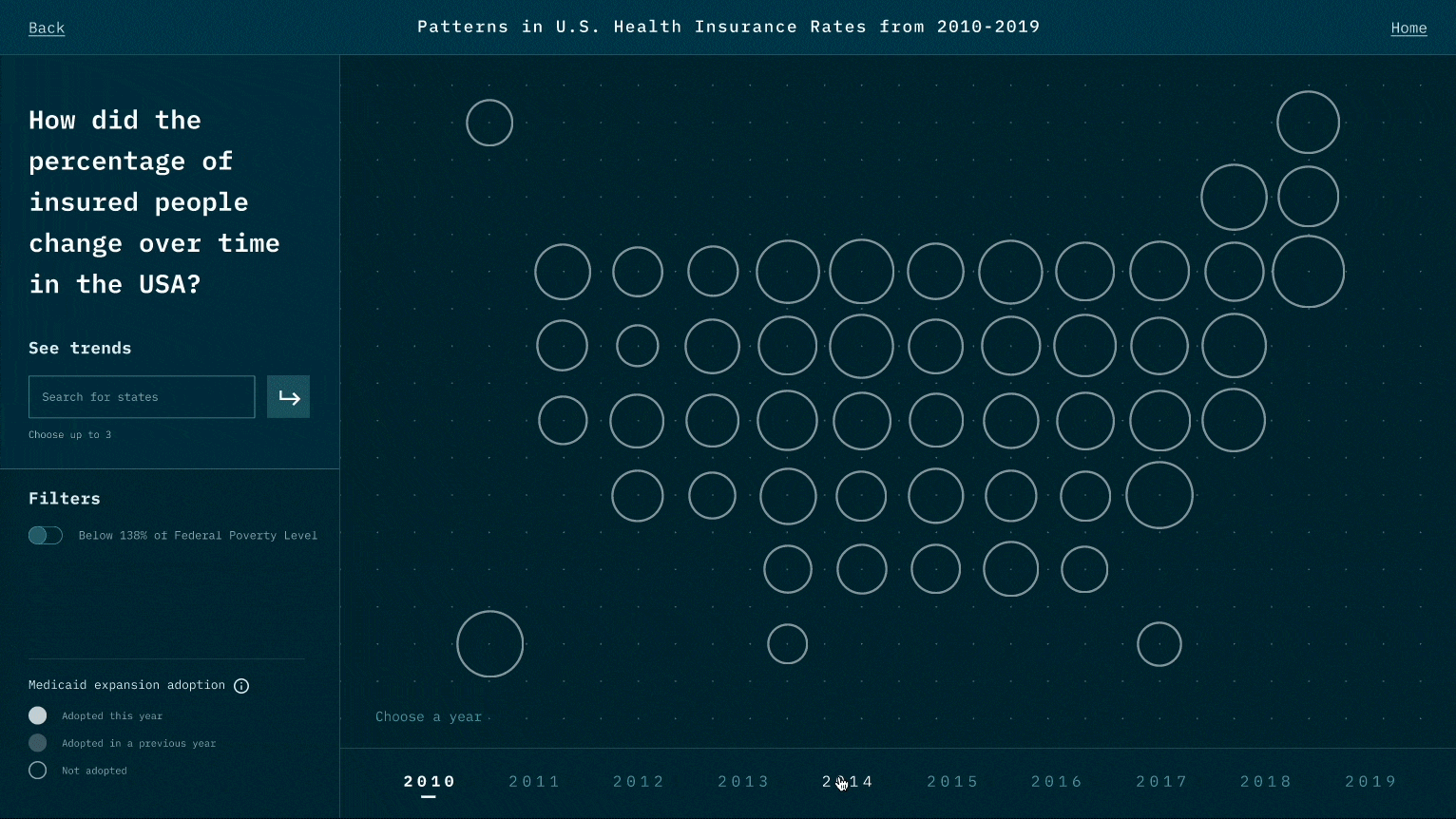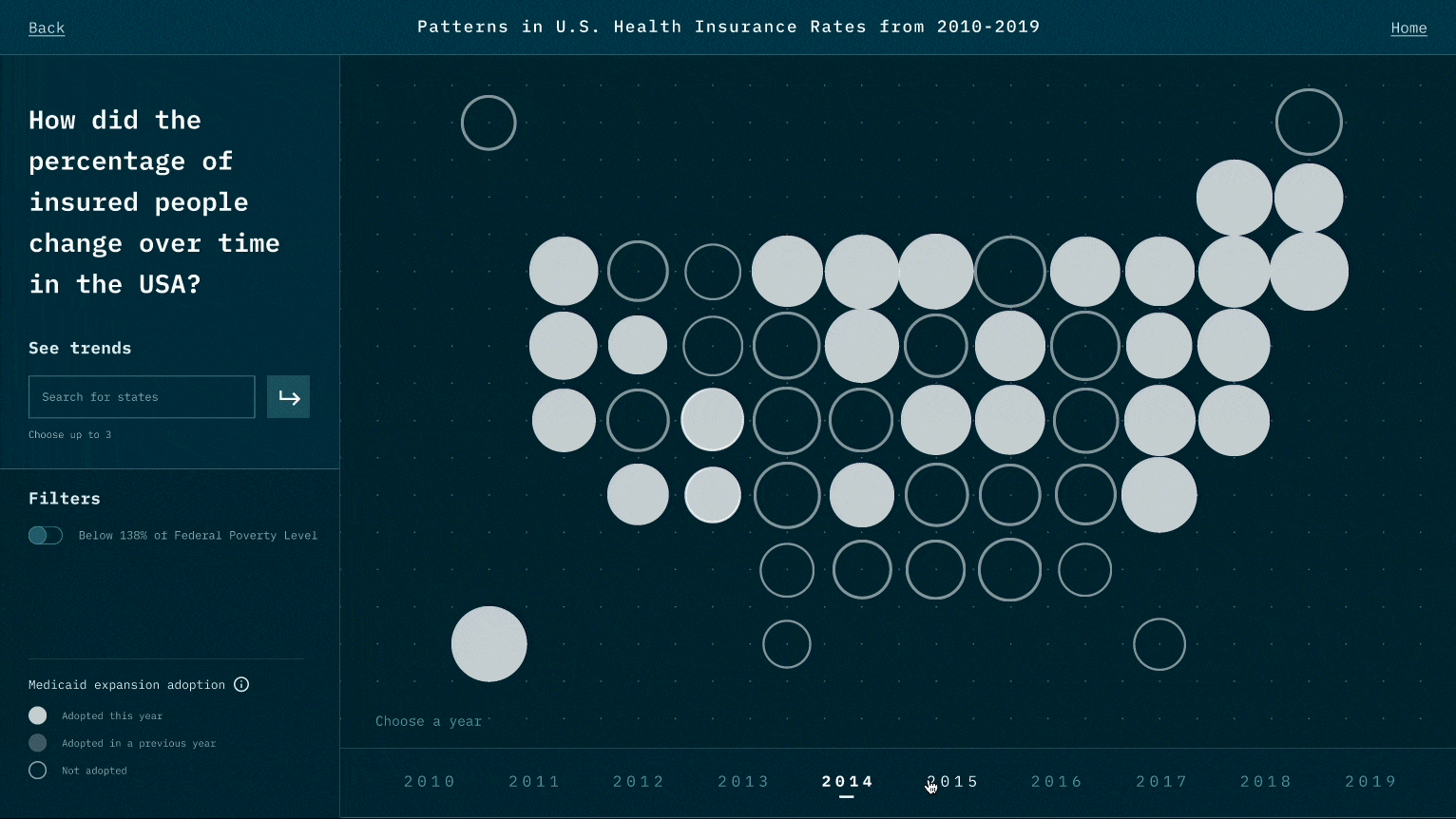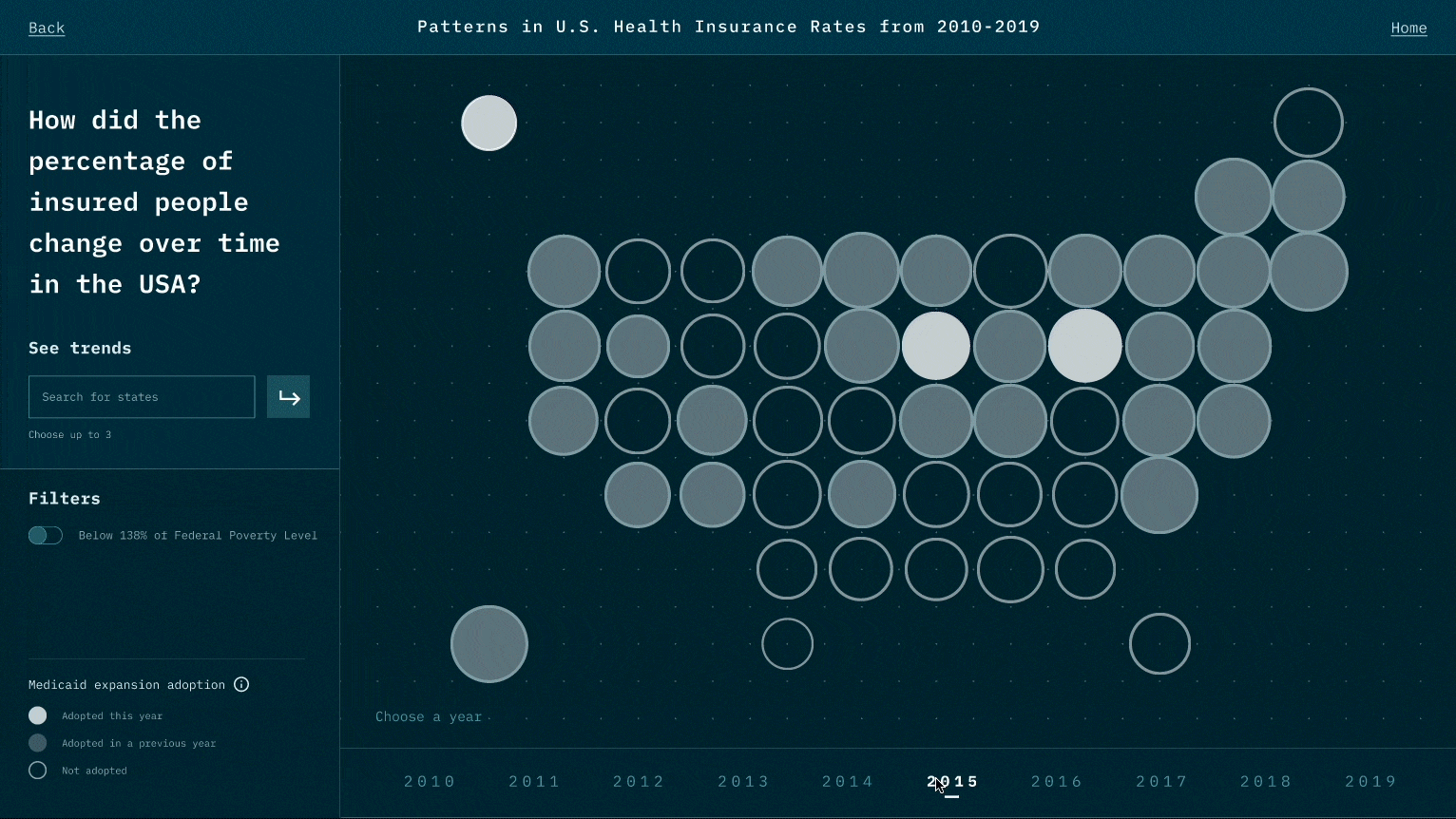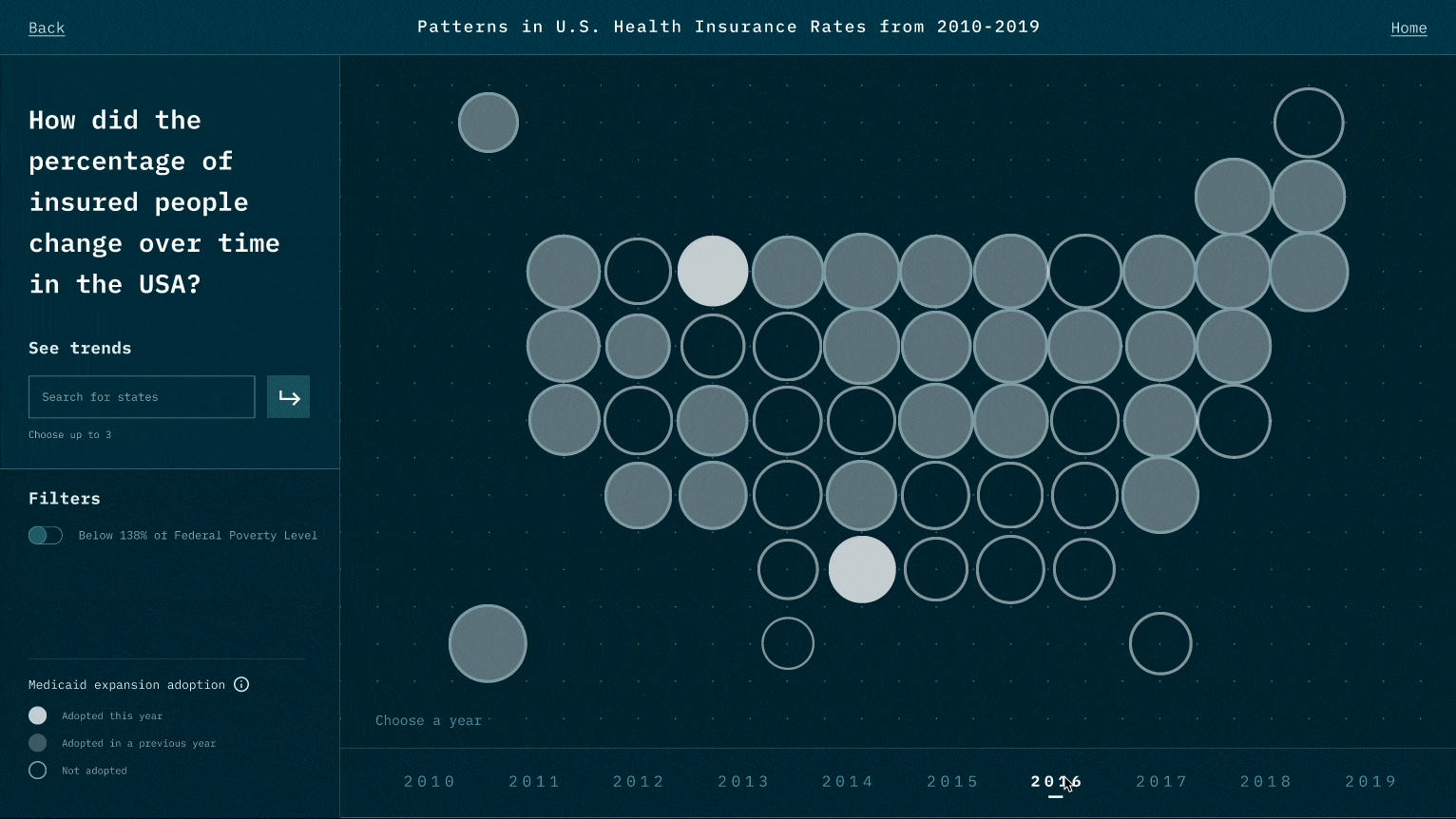
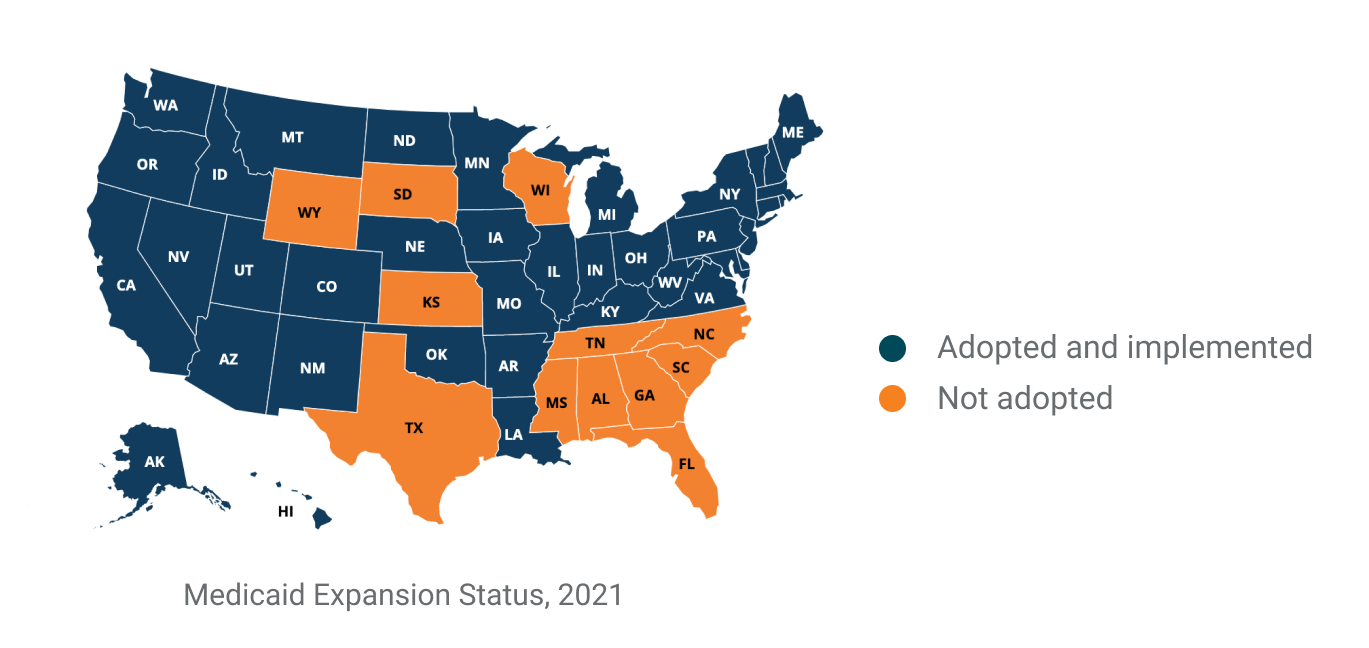
While the narrative we design is to highlight the relationship between Medicaid expansion and insured rates, viewers could also raise questions that Medicaid may not be the only reason. For example, could it be employment rate and insurance prices? This is the reflection we like viewers to think about after experiencing our visualization works.
Representation with minimal cognitive load
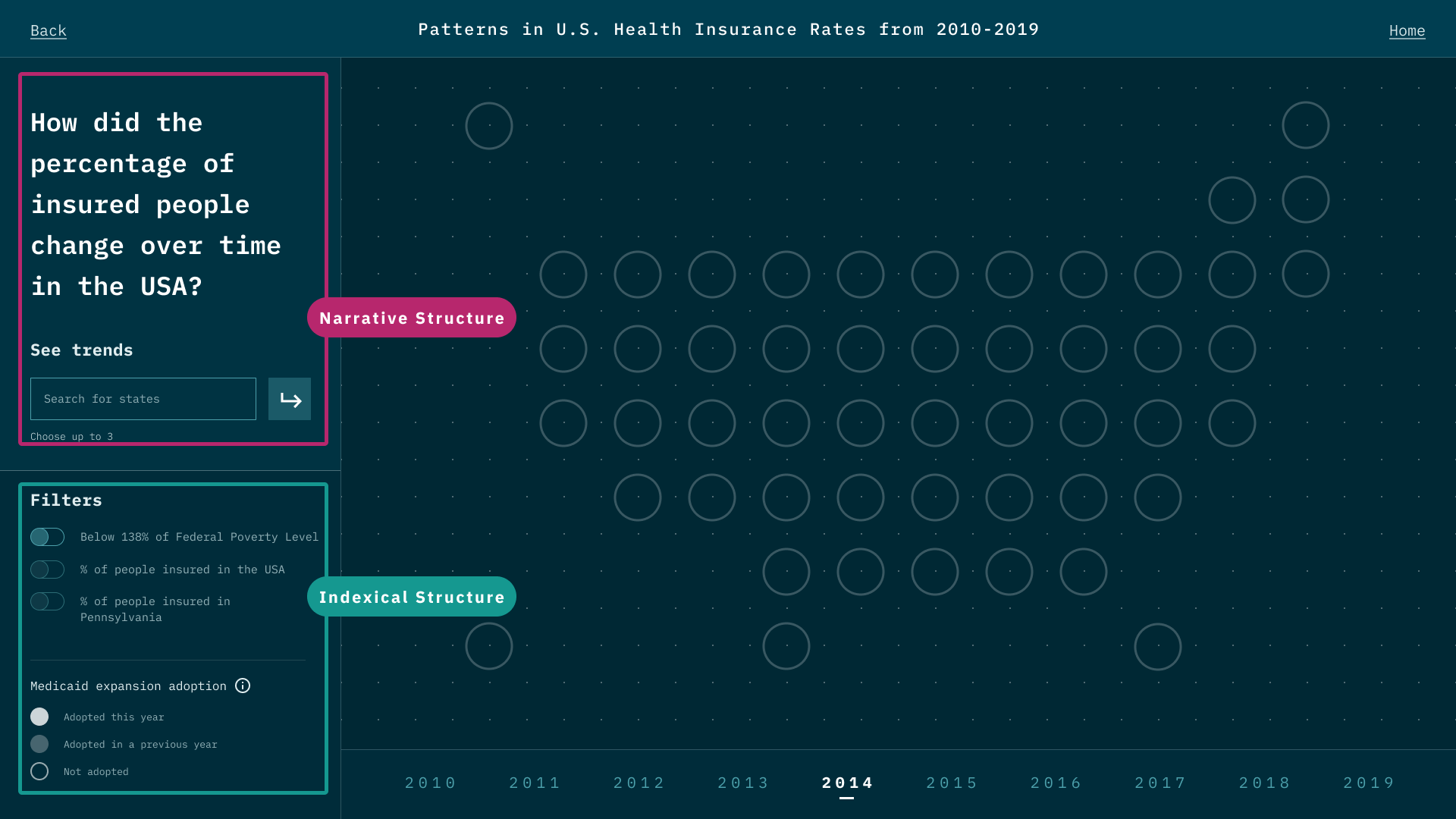
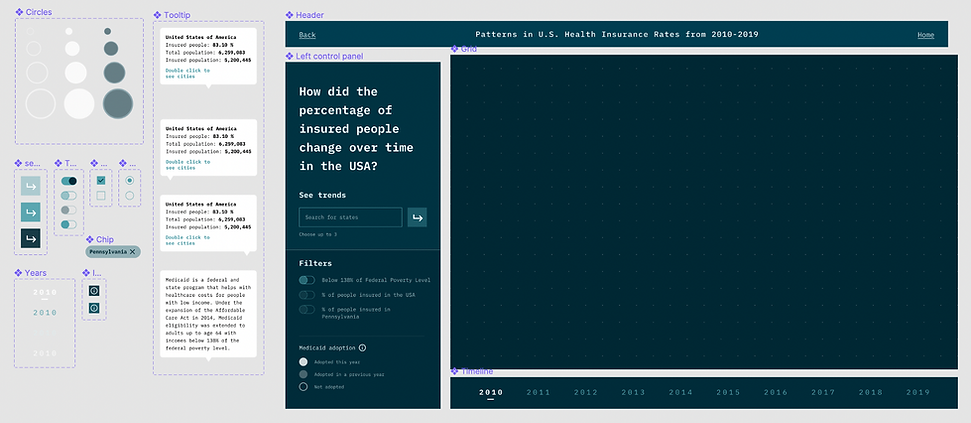
While designing the representation for each data point, we think of many representations that might look cool, such as 3D depth. However, during the test, we realize it creates a jump that requires viewers' great deal of cognitive power to create the link between data and the representation. We thereby minimize the use of representations and try to use those that are associated with existing beliefs and understandings. Also, when there is a new representation, we user motion to create a smoother transition
Data with or Without perspectives
While data itself is objective and unbiased, the way designers visualize data can inject perspectives and navigate viewers' perspectives. It is a double-edged sword. It could be a powerful tool to help people tell the story of their side, on the other hand, it could be used to twist the truth and only tell one side of the story that benefits one party.